作为全球知名的在线百科全书,维基百科已成为公众获取知识的重要门户。
这个由志愿者协作编纂的平台,以其开放性和可信度成为人们理解复杂议题的基础工具。
支撑这一知识工程的是非营利机构维基媒体基金会,其运营范围涵盖多语言百科、多媒体资料库及教育项目等多元领域。
秉承知识自由共享理念,该基金会始终提供无偿的知识服务,但近期面临人工智能浪潮的剧烈冲击。
多家科技企业为训练语言模型,部署海量自动化程序持续抓取平台数据资源。
高强度数据采集导致服务器压力激增,迫使运营方采取非常应对措施。
令人意外的是,维基媒体并未诉诸法律手段,转而选择主动妥协方案——
系统化开放数据资源。
「我们已整理结构化数据集,恳请停止自动化抓取。」

该机构近期通过Kaggle社区发布英法双语百科数据库,针对机器学习需求进行专项优化。
相较于人类可读的网页格式,技术团队将内容转化为JSON结构化数据,明确标注标题、摘要及正文层级。
这种机器友好型格式显著降低算法解析难度,为AI企业节省大量预处理成本。

此举犹如在狼群外围设置投食点,以保全核心数据生态的完整性。
运营团队透露,2024年多媒体资源下载流量激增50%,溯源发现主要来自算法采集行为。
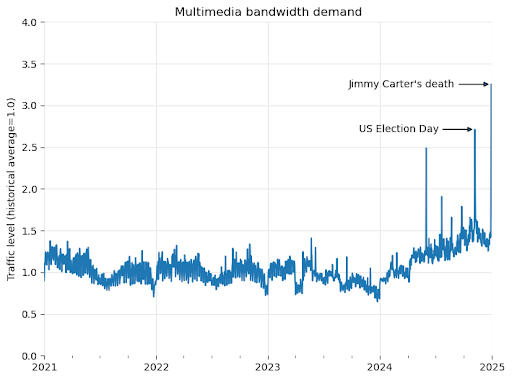
维基的全球服务器架构采用分级缓存机制:高频内容存储在区域节点,冷门数据保留于弗吉尼亚主数据中心。
自动化爬虫无视内容热度,大规模调取非缓存数据,导致国际带宽成本飙升。

监测数据显示,美国主节点65%的高价流量消耗源自AI企业,每年额外增加数百万美元运营开支。

传统反爬机制面临严峻挑战,机器人协议(robots.txt)在UA伪装技术前形同虚设。
