客畅网5月9日讯,腾讯混元团队正式发布并开源一款创新多模态视频生成解决方案HunyuanCustom。
该工具依托混元视频生成大模型(HunyuanVideo)研发,在主体连贯性表现上超越主流开源方案。
技术资料显示,该平台支持文本、图像、声音及影像数据的融合处理,为智能影像创作提供精准控制与高质量输出。
研发团队强调,系统具备单/多主体影像生成、动态配音及局部画面编辑功能,确保输出内容与输入素材高度契合。
针对创作者需要保持人物特征变更场景的需求,传统视频生成技术存在明显局限。
HunyuanCustom创新采用身份强化技术与跨模态整合架构,真正实现"影像定身份,文本创万物"的智能创作模式。
该工具覆盖短视频制作、电商展示、广告设计及影视创作等多元应用场景。
具体应用包括:广告领域快速变换商品展示背景、电商场景生成虚拟导购视频、影视行业高效制作剧情短片等专业需求。
通过独创的主体稳定性算法,系统在单人多物、复杂交互场景中均可维持特征的连续性,彻底解决人物形变与物体位移的技术难题。
目前基础版单主体生成功能已开放体验,用户可通过"模型广场-图生视频-参考生成"模块进行试用,其余功能计划五月全面开放。
单主体模式下,上传人物或物品静态图片并输入动作描述(如"骑自行车穿越林荫道"),系统即可生成具有空间连续性的动态影像。
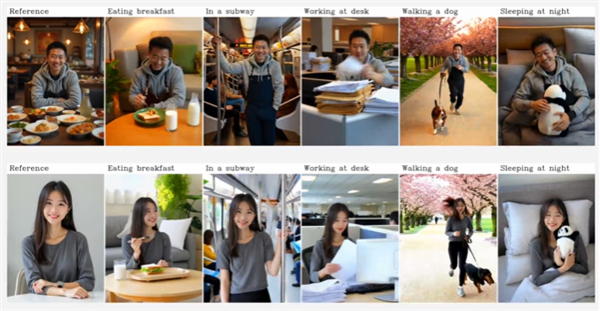
多主体创作场景中,用户可分别上传人物与物品图像,结合文字指令实现多元素的场景化编排。

系统还突破性地整合了音视频同步技术,在音频驱动模式下,结合人物肖像与声音素材,可生成虚拟主播、智能客服等场景的交互视频。

视频编辑功能支持将指定元素无缝植入现有影像素材,为影视后期制作与内容二次创作提供高效解决方案。
